July 2015
The process of searching for similar digital images in an archive, also known as content-based image retrieval (CBIR), is a challenging task due to several reasons. Firstly, determining similarity is difficult when working with visual data at the pixel level. It is not easy to answer the question of what is similar to what. Secondly, quantifying similarity poses its own challenges, as the measurement depends on the chosen method. Lastly, searching through large archives takes time and can be infeasible when dealing with big data.
In the field of medical imaging, detecting and measuring similarities in large image archives is crucial for diagnostic radiology, radiation oncology, cardiology, and other clinical areas. The accuracy and speed of image retrieval are particularly important in medical imaging, given that human life is at the center of attention. Unlike non-medical images, the overall appearance of a medical image may not be relevant. Instead, a specific region of interest (ROI), such as an organ, tumor, or specific tissue type, is typically studied. This means that many small regions of an image may be irrelevant for a specific retrieval task.
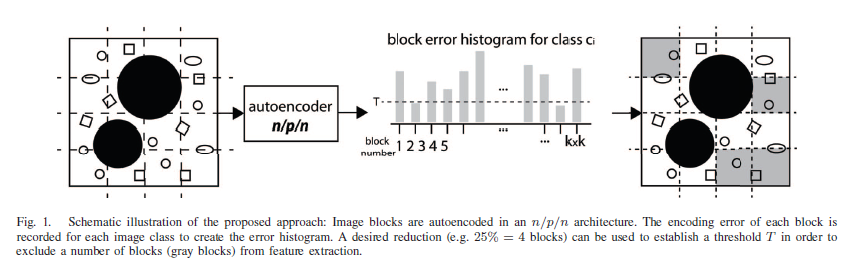
The idea proposed in the paper is to identify irrelevant image blocks within each medical image class by analyzing the error histogram of an autoencoder with a smaller hidden layer size (p) compared to the input/output layer size (n). By using an autoencoder with p < n, the encoding of significant image blocks results in a larger error, making it easier to detect irrelevant blocks. The hypothesis put forward in the paper suggests that the relevance of image blocks is directly related to the error produced by the autoencoder, assuming that the images are mostly free from noise. This approach aims to reduce the dimensionality of features for image retrieval in medical imaging.
The literature on content-based image retrieval (CBIR) is extensive, covering more than 20 years of research. This review briefly discusses major works in CBIR, explores visual features used in CBIR, and provides an overview of related research on autoencoders.
CBIR has become increasingly challenging due to diverse obstacles that hinder accurate similarity detection. Additionally, processing large image datasets in a timely manner on conventional computing devices is a daunting task. Early research in digital image search primarily focused on text-based methods for retrieving images. Surveys and reviews have provided comprehensive insights into the field, including medical image retrieval systems as a specialized subfield of CBIR. CBIR systems assist in managing and navigating through vast visual data archives by enabling searches based on textual or visual queries. While the methods applied for image representation, feature extraction, and similarity measurement vary across CBIR systems, their basic architectures are quite similar.
Feature extraction is a crucial process in CBIR, aiming to create higher-level descriptions from low-level pixel data. Recent medical image retrieval systems rely on visual features such as color, shape, texture, and spatial characteristics. These features can be categorized into low-level, middle-level, and high-level features. Initially, CBIR systems mainly employed low-level features that captured color and shape characteristics. However, there is now a demand for both mid-level (e.g., sub-image, bagging approach) and high-level (semantic) image representations. General visual features are commonly implemented in CBIR systems due to their independence from prior information and computational efficiency. The effectiveness of a CBIR system heavily relies on the quality of the extracted features, as inadequate representation may lead to difficulties in retrieving similar images.
Gray level features, particularly color, are frequently utilized in CBIR. Global gray level features can be formed by considering the local gray level features of each pixel in the image. Building a gray-level histogram is a popular method for extracting global features from medical images. However, using histograms may lead to assigning similar color intensities to different bins, and they lack spatial information. To overcome these limitations, partition-based histograms and color coherence vectors (CCV) have been developed. The gray level correlogram method aims to extract both gray-level and spatial information from an image by analyzing pixel position, intensity, probability of intensity, and distance.
Textural features play a vital role in medical imaging, as gray levels alone may not effectively discriminate objects, and texture features can provide crucial information for disease diagnosis. Textural properties include smoothness, directionality, and randomness, and different extraction methods exist, such as statistical, geometrical, and model-based approaches. Statistical methods represent textures through the statistical distribution of image intensity, while Local Binary Patterns (LBPs) are practical for quantifying gray level textures by analyzing patterns of local neighborhoods. LBPs have been widely employed in various applications, including texture classification and image retrieval, due to their low computational complexity and invariance to resolution changes. Recently, the concept of “barcodes” using Radon transform has been introduced as a new binary approach to texture description.
In multimodal searching, various strategies have been developed to incorporate multiple modalities in CBIR. These include constrained hierarchies or classes, early fusion, and late fusion methods. Constrained methods restrict the search process to specific hierarchies or classes, resulting in faster retrieval for large datasets. Image annotation and classification are often employed as initial steps to expedite image retrieval in large databases. Support Vector Machines (SVM) is a popular algorithm for reliable and fast classification, and it has been combined with other classifiers to enhance performance.
Autoencoders, a type of neural network, are used for decoding inputs with minimum error. They provide a sophisticated unsupervised learning scheme and can be applied in various domains. Autoencoders have been used for tasks such as data reconstruction, feature learning on color images, compression of mammograms, and representation learning. However, using the autoencoding error to quantify the relevance of retrieved images, particularly in the medical imaging domain, has not been extensively explored. This review proposes the use of a shallow autoencoder and the analysis of error histograms to identify and eliminate irrelevant image blocks for retrieval purposes.
Overall, this review covers major works in CBIR, discusses visual features employed in CBIR systems, and provides insights into the application of autoencoders in image retrieval tasks.
The approach proposed in this research aims to selectively eliminate irrelevant image blocks from the feature extraction process for retrieval tasks. It suggests using autoencoders, specifically shallow neural networks with high decoding errors, to identify retrieval-irrelevant regions. By analyzing the autoencoding errors of image blocks captured in a histogram matrix, the least contributing blocks can be determined.
The experiment utilizes the IRMA 2009 database, which consists of 14,410 x-ray images with 193 defined classes. The autoencoder is applied to image blocks using a restricted Boltzmann machine function, and the reduction levels are set at 1/8, 1/4, and 1/2 (corresponding to 12.5%, 25%, and 50% reduction, respectively). Precision, recall, and retrieval times are measured for different settings.
The results show that significant time savings, greater than 27%, can be achieved when 50% of the image blocks are ignored, resulting in a 50% reduction in the feature vector size. Although there is a slight decrease in accuracy (both precision and recall) of less than 1% for the top 20 retrieved images, the reduction in computation time is considered significant. It should be noted that the direct translation of space savings into computational savings may not be one-to-one due to algorithmic specifications.
Overall, the proposed approach using autoencoders for relevance quantification shows promising results in reducing computational load while maintaining reasonable retrieval accuracy for medical image retrieval tasks.
Additional details: AUTOENCODING THE RETRIEVAL RELEVANCE OF MEDICAL IMAGES